Fortran环境配置:Visual Studio和Fortran的下载以及设置MKL环境。
之前看了雷洪、胡许冰编著的《多核并行高性能计算OpenMP》这本书,也写了些代码。很久没用了,现在重新整理记录下。或许之后还会用上,添几行代码就可以省去手动并行的麻烦。本篇的内容主要是参考这本书,也有自己写的一些东西。
首先了解下背景
OpenMP(Open Multi-Processing)是共享内存模式的,因此它可以在一个节点上使用多个核并行。使用方法比较简单,通过一套并行描述的注释来指导多线程的计算。
如果是需要使用不同的计算节点同时计算,则要考虑不同节点之间的通信问题,需要用上消息传递界面(Meassage Passing Interface, MPI)。MPI编程相对来说较难,我自己就不折腾了,如果迫不得已要用到可以再接触。
虽然说OpenMP可以在一个节点上轻松实现并行,但很多情况下是做不到。比如两个步骤之间参数有强烈的依赖关系,这时候就不适合并行。有时过多的并行也会导致速度减慢,因为消息传递也会产生开销。而且使用MKL库时,如果链接设置好的话,很多函数会自动并行运算,也就是已经占用了该节点的部分核资源,这时候再并行的空间就不多了。
对于科学计算来说,大部分运算时间都是耗在重复的计算上,比如“扫点”,“变化参数”等。这种计算关联度不大,很容易用OpenMP实现并行,可以免去了手动并行的麻烦。如果在这个“外循环”上实现并行,基本上就已经把一个节点的所有核占满,因此就没有必要再考虑算法上的并行了(而且算法关联度大,并行也不好实现)。
OpenMP的基本原理和规则
OpenMP执行方式是串行→并行→串行→并行→串行……的过程。
在Fortran程序中,是用!$OMP PARALLEL和!$OMP END PARALLEL来表示一个并行程序块。这看起来像注释一样,但是有起效果的。
并行时需要处理好串行和并行变量之间关系,有PRIVATE子句、SHARED子句等。PRIVATE是并行的时候会产生副本,需要注意的是该副本是没有初始值的,即使串行中已经赋了值。SHARED是共享变量,并行时会产生数据竞争,在程序上避免冲突。此外,还有其他子句,如FIRSTPRIVATE子句、LASTPRAIVATE子句、COPYIN子句、COPYPRIVATE子句等,这里暂不提及。
此外,还有很多其他内容这里都不讲了,有想要了解的可以看这本书。这里我就直接翻到最喜爱的do循环并行部分,因为之后大部分会用上这个。书中也是这么认为的,原文如下:
“循环的并行化是利用OpenMP进行程序并行计算的最关键部分。因为很多科学计算程序,尤其是涉及矩阵求解运算的程序,将大量的计算时间消耗在对循环计算的处理上,因此循环的并行化在OpenMP程序中是一个相对独立并且十分重要的组成部分。”
Do循环并行的语句:以!$OMP PARALLEL和!$OMP DO开始,以 !$OMP END DO和!$OMP END PARALLEL结束。
该语句可以缩写为:以!$OMP PARALLEL DO开始,以!$OMP END PARALLEL DO结束。
下面贴出Fortran代码(这里循环并行时默认为私有变量,把需要的参数以及各节点计算结果的存放器作为共享变量):
! This code is supported by the website: https://www.guanjihuan.com
! The newest version of this code is on the web page: https://www.guanjihuan.com/archives/764
program hello_open_mp
use omp_lib !这里也可以写成 include 'omp_lib.h' ,两者调用方式均可
integer mcpu,tid,total,N,i,j,loop
double precision starttime, endtime, time,result_0
double precision, allocatable:: T(:)
N=5 ! 用于do并行
loop=1000000000 !如果要测试并行和串行运算时间,可以加大loop值
allocate(T(N))
!call OMP_SET_NUM_THREADS(2) !人为设置线程个数,可以取消注释看效果
total=OMP_GET_NUM_PROCS() ! 获取计算机系统的处理器数量
print '(a,i2)', '计算机处理器数量:' , total !也可以用write(*,'(a,i2)')来输出
print '(a)', '-----在并行之前-----'
tid=OMP_GET_THREAD_NUM() !获取当前线程的线程号
mcpu=OMP_GET_NUM_THREADS() !获取总的线程数
print '(a,i2,a,i2)', '当前线程号:',tid,';总的线程数:', mcpu
print * !代表换行
print'(a)','-----第一部分程序开始并行-----'
!$OMP PARALLEL DEFAULT(PRIVATE) ! 这里用的是DEFAULT(PRIVATE)
tid=OMP_GET_THREAD_NUM() !获取当前线程的线程号
mcpu=OMP_GET_NUM_THREADS() !获取总的线程数
print '(a,i2,a,i2)', '当前线程号:',tid,';总的线程数:', mcpu
!$OMP END PARALLEL
print * !代表换行
print'(a)','-----第二部分程序开始并行-----'
starttime=OMP_GET_WTIME() !获取开始时间
!$OMP PARALLEL DO DEFAULT(PRIVATE) SHARED(T,N,loop) ! 默认私有变量,把需要的参数以及各节点计算结果的存放器作为共享变量。
do i=1,N !这里放上do循环体。是多个样品。
result_0=0
tid=OMP_GET_THREAD_NUM() !获取当前线程的线程号
mcpu=OMP_GET_NUM_THREADS() !获取总的线程数
do j=1,loop !这代表我们要做的计算~
result_0 = result_0+1 !这代表我们要做的计算~
enddo !这代表我们要做的计算~
T(i) = result_0-loop+i !将各个线程的计算结果保存到公共变量中去。
!这里i代表各个循环的参数,之后如果有需要可以根据参数再整理数据。
print '(a,i2, a, f10.4,a,i2,a,i2 )', 'T(',i,')=', T(i) , ' 来源于线程号',tid,';总的线程数:', mcpu
enddo
!$OMP END PARALLEL DO !并行结束
endtime=OMP_GET_WTIME() !获取结束时间
time=endtime-starttime !总运行时间
print '(a, f13.5)' , '第二部分程序按并行计算所用的时间:', time
print * !代表换行
print'(a)','-----第二部分程序按串行的计算-----'
starttime=OMP_GET_WTIME() !获取开始时间
do i=1,N
result_0=0
tid=OMP_GET_THREAD_NUM() !获取当前线程的线程号
mcpu=OMP_GET_NUM_THREADS() !获取总的线程数
do j=1,loop
result_0 = result_0+1
enddo
T(i) = result_0-loop+i
print '(a,i2, a, f10.4,a,i2,a,i2 )', 'T(' ,i,')=', T(i) , ' 来源于线程号',tid,';总的线程数:', mcpu
enddo
endtime=OMP_GET_WTIME() !获取结束时间
time=endtime-starttime !总运行时间
print '(a, f13.5)' , '第二部分程序按串行计算所用的时间:', time
print * !代表换行
tid=OMP_GET_THREAD_NUM() !获取当前线程的线程号
mcpu=OMP_GET_NUM_THREADS() !获取总的线程数
print '(a,i5,a,i5)', '当前线程号:',tid,';总的线程数:', mcpu
print * !代表换行
end program hello_open_mp ! 这里可以写成end, 也可以写成end program,都可以。
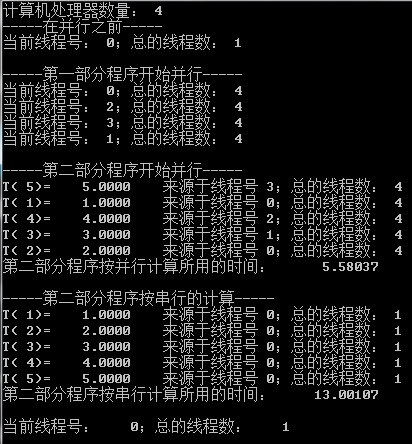
运算结果如下:
【说明:本站主要是个人笔记和代码的分享,内容可能会不定期修改。目前文章支持直接转载,引用或转载请注明出处:https://www.guanjihuan.com 。本站采用知识共享署名许可协议 CC BY】