K-means 聚类是一种常用的无监督学习算法,用于将数据分成不同的簇(群组)。其基本思想是将数据点分配到 K 个簇中,使得每个簇内的数据点尽可能地相似,同时不同簇之间的数据点差异尽可能大。K-means 算法的核心思想是 最小化簇内的平方误差。
具体的公式和算法步骤这里暂不给出,感兴趣的可以自行查询。
这里给出一个 Python 代码实现的示例:
"""
This code is supported by the website: https://www.guanjihuan.com
The newest version of this code is on the web page: https://www.guanjihuan.com/archives/44839
"""
import os
os.environ["OMP_NUM_THREADS"] = "1" # KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting this environment variable
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=300, centers=4, random_state=42) # 生成示例数据(四类)
print(X.shape)
print(y.shape)
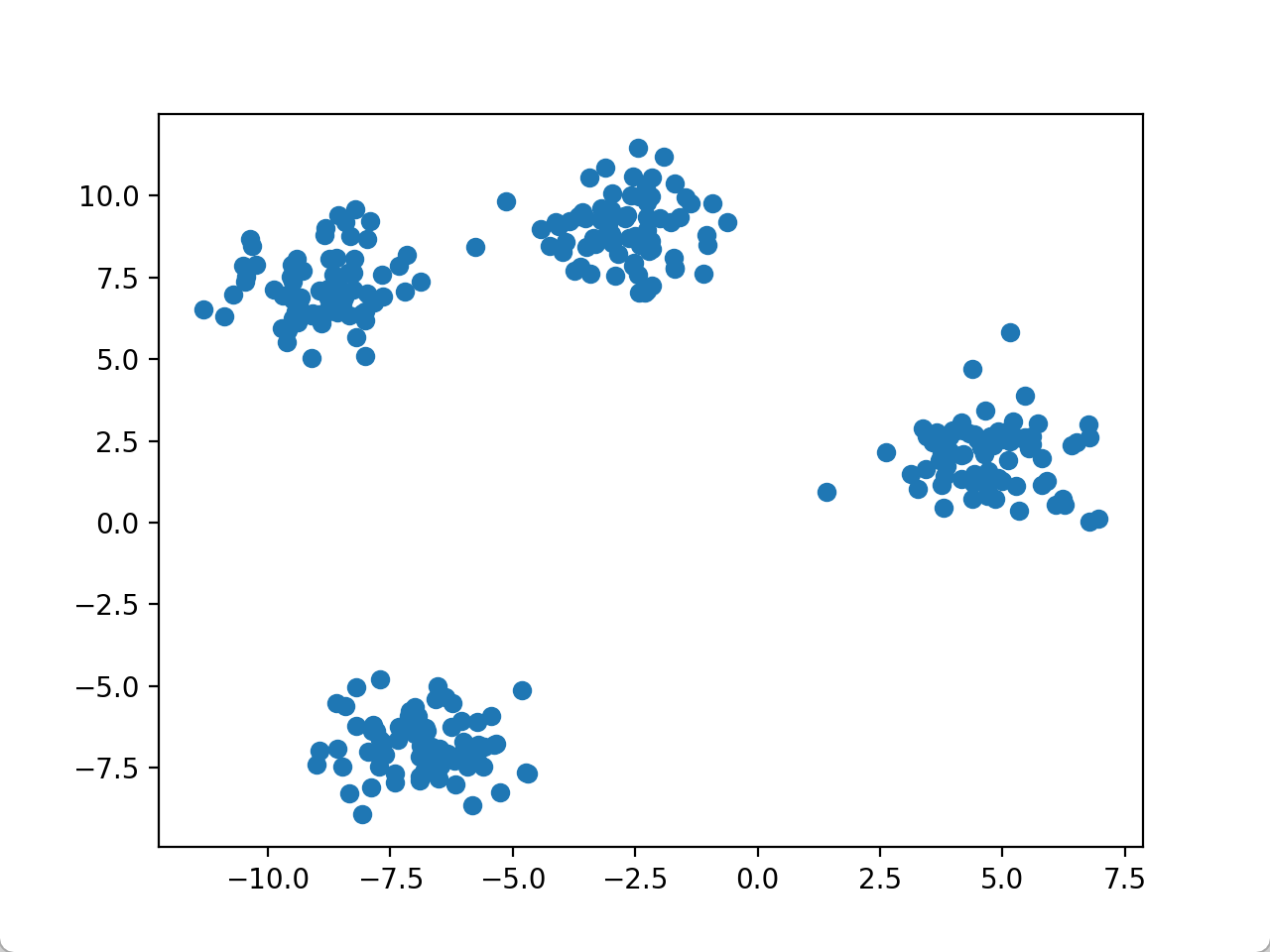
plt.scatter(X[:, 0], X[:, 1]) # 显示数据
plt.show()
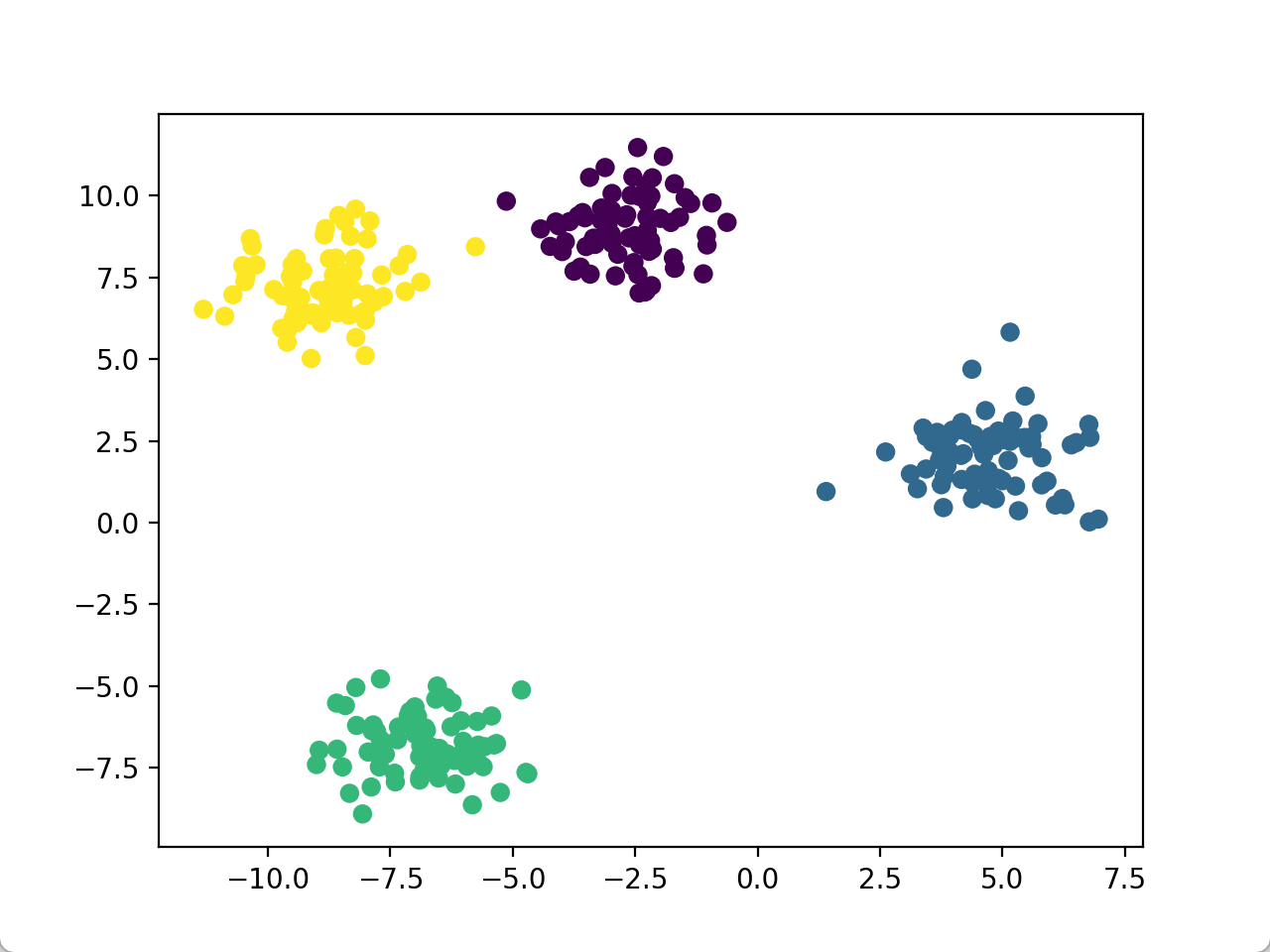
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis') # 通过颜色显示数据原有的标签
plt.show()
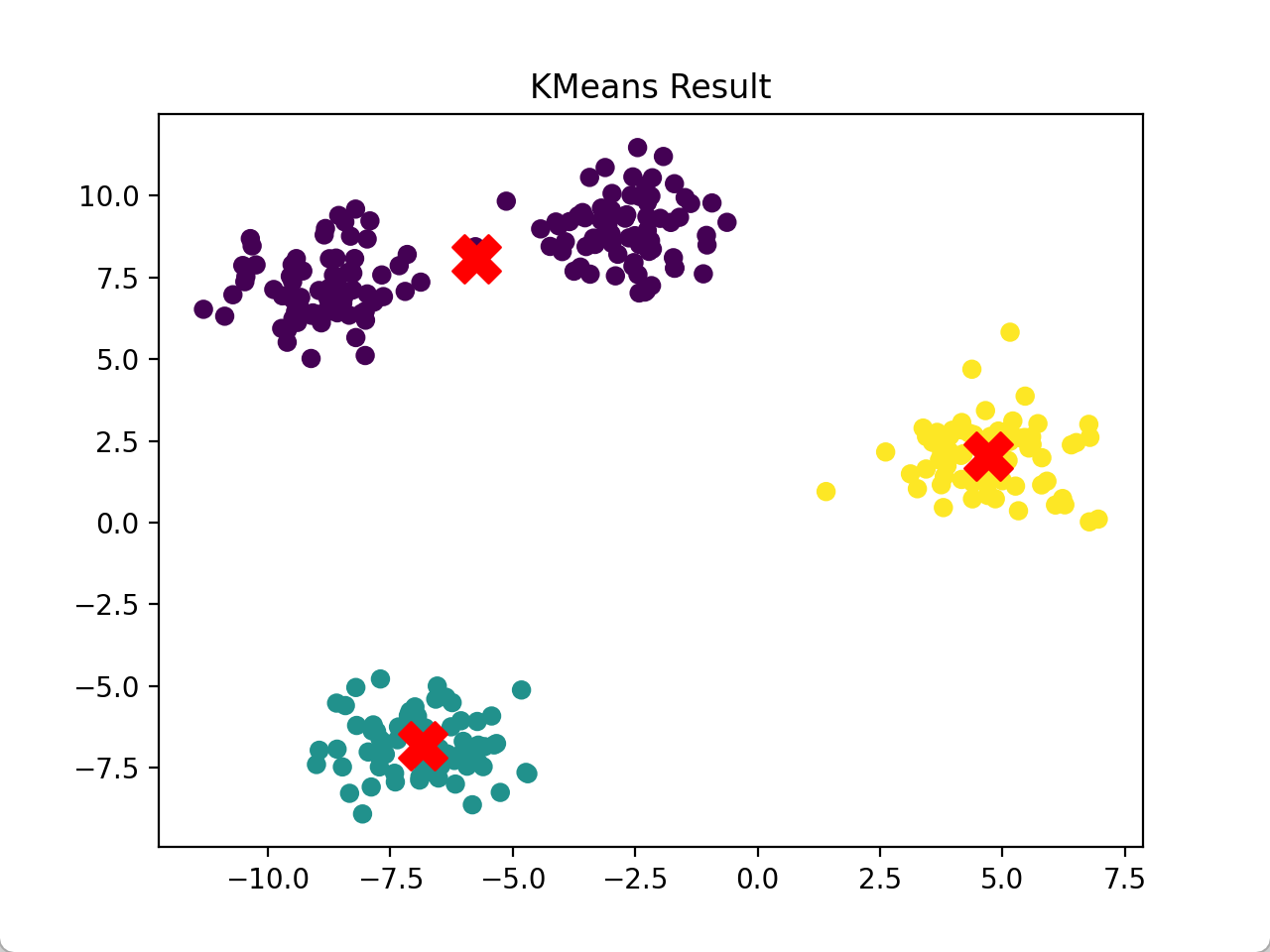
kmeans = KMeans(n_clusters=3, random_state=42) # 进行 KMeans 聚类(这里分为三类)
kmeans.fit(X)
labels = kmeans.labels_ # 获取聚类的标签
print(labels.shape)
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis') # 绘制聚类结果
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', marker='X') # 绘制聚类中心
plt.title('KMeans Result')
plt.show()运行结果:
【说明:本站主要是个人的一些笔记和代码分享,内容可能会不定期修改。为了使全网显示的始终是最新版本,这里的文章未经同意请勿转载。引用请注明出处:https://www.guanjihuan.com】
Great work on sharing the code for K-means clustering! A small tip: when selecting the number of clusters (k), consider using the Elbow Method or Silhouette Score to help determine the optimal value of k. It can be really helpful in preventing overfitting or underfitting by evaluating how well the data fits different values of k. Keep up the good work!
Thanks