说明:目前已经有ChatGLM3-6B,链接为 https://github.com/THUDM/ChatGLM3,以及有 GLM-4 模型,链接为 https://github.com/THUDM/GLM-4。
推荐阅读:对话模型chat.guanjihuan.com的主要实现代码开源。
在具有硬件条件的前提下,个人是建议安装本地的大语言模型,用于论文润色、数据处理等有一定保密需求的场景,而不是使用联网的模型,例如ChatGPT、文心一言等。
本篇记录下安装开源双语对话语言模型 ChatGLM2-6B 的步骤,具体可以阅读:https://github.com/THUDM/ChatGLM2-6B。该模型由清华大学THUDM发布。运行该模型对系统的硬件配置有一定的要求:如果是 GPU 运行需要 13GB 显存;如果是 CPU 运行需要 25GB 内存。如果以INT4量化方式加载模型,配置要求可以降低到 6GB 的显存。
下载文件:
git clone https://github.com/THUDM/ChatGLM2-6B使用 pip 安装依赖:
cd ChatGLM2-6B
pip install -r requirements.txt运行:
python cli_demo.py除了在命令行界面上运行该软件,也可以在网页上运行:python web_demo.py 或 streamlit run web_demo2.py。推荐使用第二个命令,即:
streamlit run web_demo2.py以上命令只在内网的默认页面上访问,如果需要在公网IP下访问,使用命令:
streamlit run web_demo2.py --server.port 8501 --server.address 0.0.0.0运行效果:
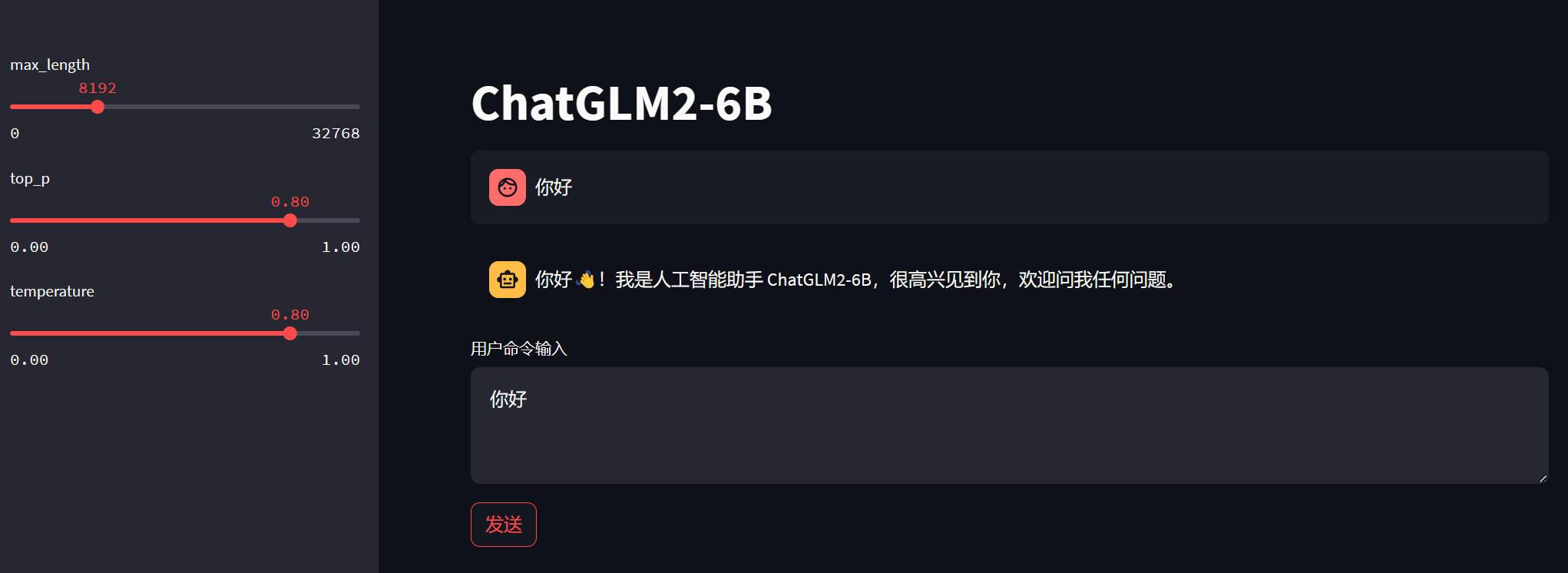
以下为一些细节和报错的解决,供参考。
第一次运行时可能会自动下载所需要的模型文件到缓存区域,有十个G左右的大小。
也可以手动下载所有的模型文件到“ChatGLM2-6B/THUDM/chatglm2-6b/”文件夹中:https://huggingface.co/THUDM/chatglm2-6b/tree/main。
为了防止一些报错,最好更新一下系统驱动(在ubuntu系统下的命令):
sudo apt-get update
sudo apt-get install ubuntu-drivers-common
sudo ubuntu-drivers autoinstall以上最后一个命令可以试着运行两次或三次,确保驱动完全更新。更新后,记得重启一下。
除了上面pip安装依赖包外,有时还会出现其他bug,可能可以通过以下方式解决:更新 Pytorch,参考:https://pytorch.org/get-started/locally/;更新transformers,使用命令:conda install -c conda-forge transformers。
如果出现报错:“FileNotFoundError: [Errno 2] No such file or directory: 'aplay'”,可以使用这个命令解决:apt-get install alsa-utils。
如果出现报错 “'ChatGLMTokenizer' object has no attribute 'tokenizer'. ”,可能是transformers版本过高,可能可以通过以下解决:
pip uninstall transformers
pip install transformers==4.33.2如果出现报错“Library cudart is not initialized”,可能可以通过以下解决:
conda install cudatoolkit=11.7 -c nvidia【说明:本站主要是个人的一些笔记和代码分享,内容可能会不定期修改。为了使全网显示的始终是最新版本,这里的文章未经同意请勿转载。引用请注明出处:https://www.guanjihuan.com】