把客观世界的信息存入计算机中通常需要有一个编码的过程。例如对于物理体系,一般需要对原子、轨道等基矢进行编码,之后才能进行计算,参考这篇:方格子模型在实空间中的哈密顿量形式。不同的编码方式对结果没有本质上的影响。
本篇讲的是字符的编码方式。常见的字符编码方式有:ASCII、GB2312、GBK、GB18030、UTF8。目前用的比较多的是GBK和UTF8。
一、编码的大小
- ASCII 为1个字节(1 Byte,8 bits),最高位是0。
- GB2312 为1~2个字节(1~2 Byte),共收录了6763个汉字。
- GBK 为1~2个字节(1~2 Byte),共收录了21003个汉字,包含繁体字等。
- GB18030 为1~4个字节(1~4 Byte),共收录了70244个汉字,包含少数民族文字等。
- UTF8 为1~4个字节(1~4 Byte),是通用的编码方式。
大多数网页采用的是UTF8编码,所以网页源码一般都有<meta charset="UTF-8">的标签。
Python查看字符编码的例子:
"""
This code is supported by the website: https://www.guanjihuan.com
The newest version of this code is on the web page: https://www.guanjihuan.com/archives/23000
"""
string_array = ['关', '。', '3', '.']
for string in string_array:
# 编码
gb2312 = string.encode(encoding="gb2312")
gbk = string.encode(encoding="gbk")
gb18030 = string.encode(encoding="gb18030")
uft8 = string.encode(encoding="utf-8")
# 查看
print('字符串 =', string, ' | 数据类型 =', type(string), ' | 长度 =', len(string))
print('gb2312编码 =', gb2312, ' | 数据类型 =', type(gb2312), ' | 长度 =', len(gb2312))
print('gbk编码 =', gbk, ' | 数据类型 =', type(gbk), ' | 长度 =', len(gbk))
print('gb18030编码 =', gb18030, ' | 数据类型 =', type(gb18030), ' | 长度 =', len(gb18030))
print('utf8编码 =', uft8, ' | 数据类型 =', type(uft8), ' | 长度 =', len(uft8))
print()
# 乱码例子
string = '关关'
uft8 = string.encode(encoding="utf-8")
new_string_1 = uft8.decode(encoding="utf-8")
new_string_2 = uft8.decode(encoding="gbk")
print("使用utf-8解码utf-8编码的数据 =", new_string_1)
print("使用gbk解码utf-8编码的数据 =", new_string_2)运行结果:
字符串 = 关 | 数据类型 = <class 'str'> | 长度 = 1
gb2312编码 = b'\xb9\xd8' | 数据类型 = <class 'bytes'> | 长度 = 2
gbk编码 = b'\xb9\xd8' | 数据类型 = <class 'bytes'> | 长度 = 2
gb18030编码 = b'\xb9\xd8' | 数据类型 = <class 'bytes'> | 长度 = 2
utf8编码 = b'\xe5\x85\xb3' | 数据类型 = <class 'bytes'> | 长度 = 3
字符串 = 。 | 数据类型 = <class 'str'> | 长度 = 1
gb2312编码 = b'\xa1\xa3' | 数据类型 = <class 'bytes'> | 长度 = 2
gbk编码 = b'\xa1\xa3' | 数据类型 = <class 'bytes'> | 长度 = 2
gb18030编码 = b'\xa1\xa3' | 数据类型 = <class 'bytes'> | 长度 = 2
utf8编码 = b'\xe3\x80\x82' | 数据类型 = <class 'bytes'> | 长度 = 3
字符串 = 3 | 数据类型 = <class 'str'> | 长度 = 1
gb2312编码 = b'3' | 数据类型 = <class 'bytes'> | 长度 = 1
gbk编码 = b'3' | 数据类型 = <class 'bytes'> | 长度 = 1
gb18030编码 = b'3' | 数据类型 = <class 'bytes'> | 长度 = 1
utf8编码 = b'3' | 数据类型 = <class 'bytes'> | 长度 = 1
字符串 = . | 数据类型 = <class 'str'> | 长度 = 1
gb2312编码 = b'.' | 数据类型 = <class 'bytes'> | 长度 = 1
gbk编码 = b'.' | 数据类型 = <class 'bytes'> | 长度 = 1
gb18030编码 = b'.' | 数据类型 = <class 'bytes'> | 长度 = 1
utf8编码 = b'.' | 数据类型 = <class 'bytes'> | 长度 = 1
使用utf-8解码utf-8编码的数据 = 关关
使用gbk解码utf-8编码的数据 = 鍏冲叧可以看出:
- 对于中文字符(非ASCII字符),国标GB编码大部分为2个字节,UTF8编码大部分为3个字节。对于ASCII字符,始终是1个字节。
- 对于中文字符(非ASCII字符),国标GB编码和UTF8互相不兼容。
二、编码的兼容性
编码之间的兼容性如下图所示[1],国标GB编码和UTF8互相不兼容,这也就是为什么日常会看到文件的乱码:通过UTF8的编码方式打开国标GB编码的文件,或用国标GB的编码方式打开UTF8编码的文件。
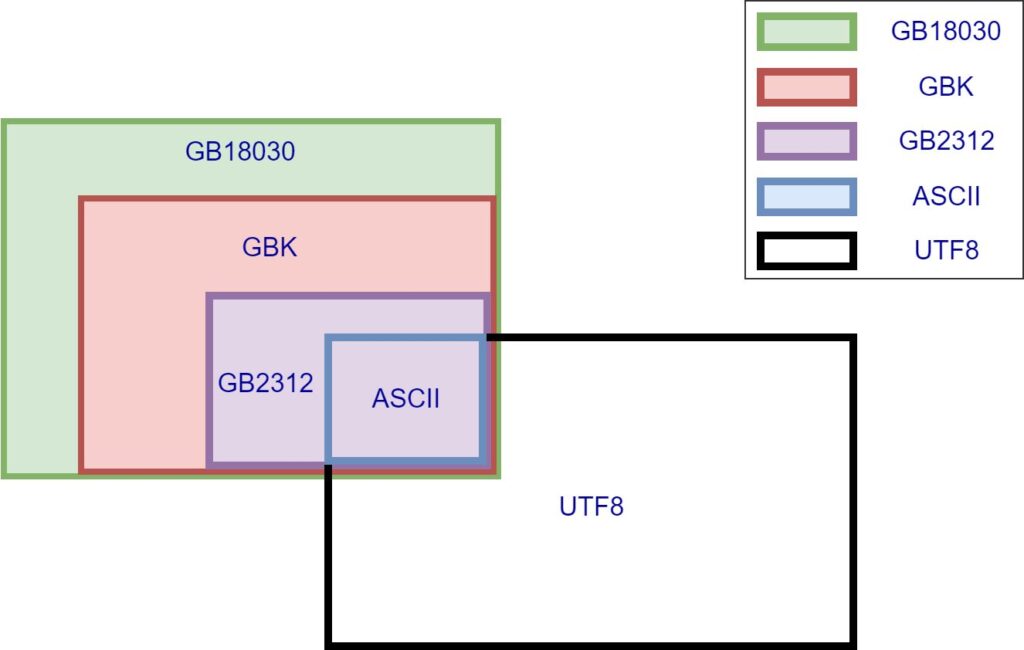
ASCII编码几乎被世界上所有编码所兼容,除了UTF16和UTF32编码[1]。
参考资料:
[2] https://baike.baidu.com/item/信息交换用汉字编码字符集
[3] https://baike.baidu.com/item/GBK字库
[4] https://baike.baidu.com/item/GB18030/3204518
[5] https://baike.baidu.com/item/UTF-8/481798
【说明:本站主要是个人的一些笔记和代码分享,内容可能会不定期修改。为了使全网显示的始终是最新版本,这里的文章未经同意请勿转载。引用请注明出处:https://www.guanjihuan.com】