卷积(convolution)和池化(pooling)是卷积神经网络(convolutional neural network, CNN)中的两个重要操作。卷积的作用是提取输入数据的局部特征。池化的作用是对卷积后的特征映射进行下采样,降低分辨率,从而减小计算量和参数空间。
一、卷积
想象你在看一张图片,这张图片上有很多小元素,比如线条、圆形等。如果你只是盯着整张图片看,可能很难看清细节,但如果你用一个小窗口在图片上滑动观察,每次只关注窗口内的那一小部分,就能更容易看清里面的元素。卷积的作用是在输入数据(如图像)上滑动一个小滤波器,来自动学习局部特征模式,如边缘、纹理等。通过多层卷积,可以逐步从低级特征组合出更高层次的复杂特征表示。
个人理解:相较于全连接层,卷积层的主要特点可以概括为“先局部,后整体”。其中,局部特征通过训练后的卷积核来体现,尤其是二维卷积核可以很好地提取图像的信息,而全连接层一开始就把数据展平(flattened),因此很难获取到图像所要表达的意思。
卷积公式(二维离散形式):

卷积的二维连续形式:

卷积的一维连续形式:

卷积过程的动图:
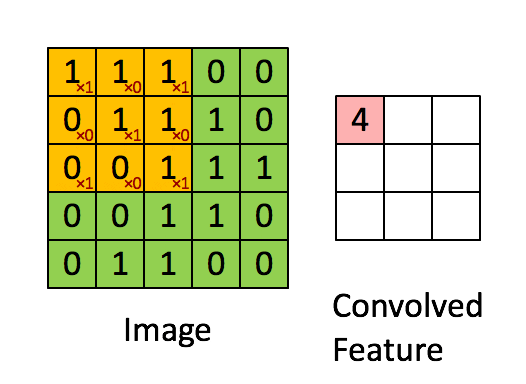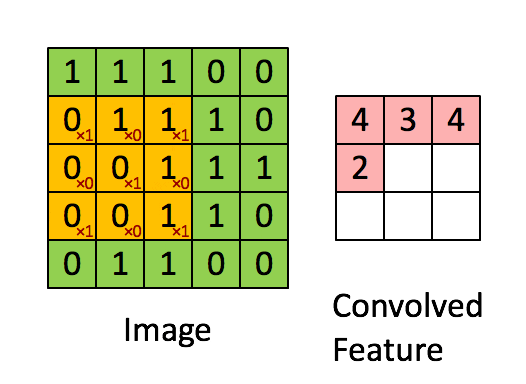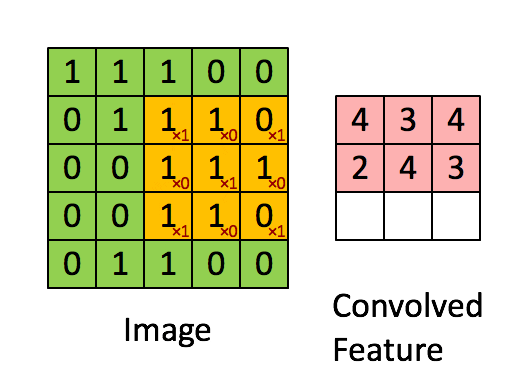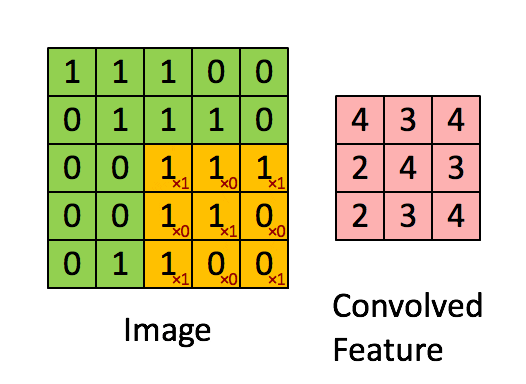
卷积的 Pytorch 文档:
- torch.nn.Conv1d():https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
- torch.nn.Conv2d():https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
- torch.nn.Conv3d():https://pytorch.org/docs/stable/generated/torch.nn.Conv3d.html
可能要考虑的参数:
- kernel_size:卷积核的大小决定了每次卷积操作覆盖输入的区域大小。卷积核的具体数值在训练过程是不断更新的。
- stride:步幅是指卷积核每次在输入上滑动的步长。默认为 1,即移动一个像素。
- padding:填充是指在输入的周围添加额外的像素值。填充的目的通常是为了保持输出的大小与输入相同,或者在进行卷积运算时保持边界信息。默认为 0,即不进行填充。
- dilation:扩张率控制了卷积核中元素之间的间隔。默认为 1,即元素之间没有间隔。
代码示例:
import torch
input_data = torch.randn(1, 1, 28, 28)
conv_layer = torch.nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1)
output_data = conv_layer(input_data)
print("输出数据的形状:", output_data.shape)
conv_layer = torch.nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0)
output_data = conv_layer(input_data)
print("输出数据的形状:", output_data.shape)运行结果:
输出数据的形状: torch.Size([1, 64, 28, 28])
输出数据的形状: torch.Size([1, 64, 26, 26])二、池化
池化的方式有最大池化和平均池化等,它们分别取局部区域的最大值和平均值作为输出。其中,最大池化可能会更常用些,因为最大池化是在每个池化窗口中选择最大值作为输出,这样可以保留图像中最显著的特征。
池化过程的动图(以最大池化为例):
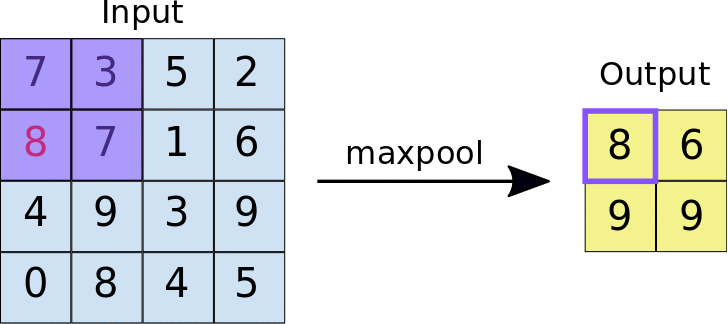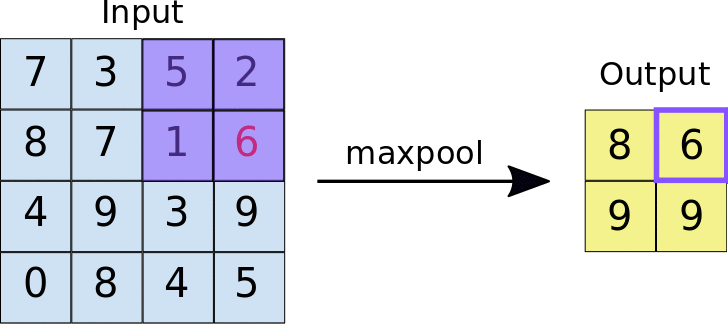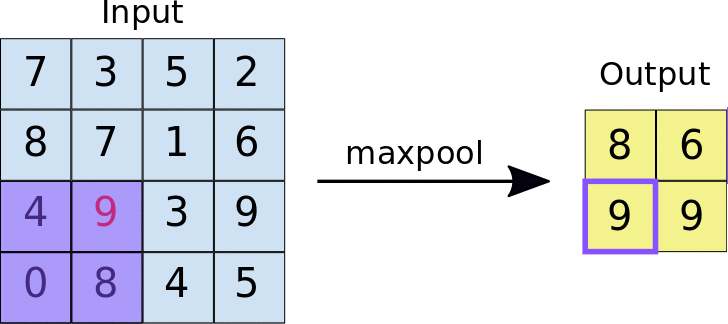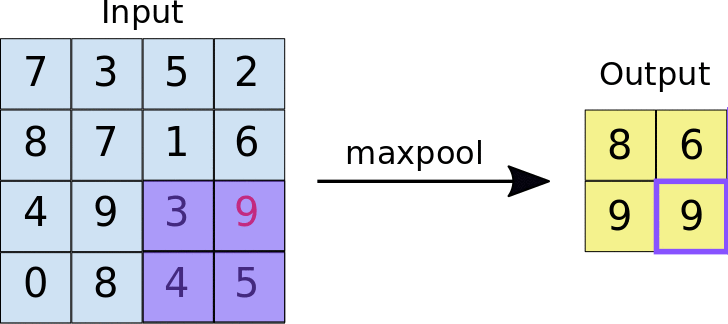
最大池化的 Pytorch 文档:
- torch.nn.MaxPool1d():https://pytorch.org/docs/stable/generated/torch.nn.MaxPool1d.html
- torch.nn.MaxPool2d():https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html
- torch.nn.MaxPool3d():https://pytorch.org/docs/stable/generated/torch.nn.MaxPool3d.html
代码示例:
import torch
input_data = torch.tensor([[7, 3, 5, 2],
[8, 7, 1, 6],
[4, 9, 3, 9],
[0, 8, 4, 5]], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 两次 .unsqueeze(0) 分别是添加批次和通道维度
max_pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)
output_data = max_pool(input_data)
print("Input:\n", input_data)
print("Output after max pooling:\n", output_data)
print('输入数据的形状: ', input_data.shape)
print('输出数据的形状: ', output_data.shape)运行结果:
Input:
tensor([[[[7., 3., 5., 2.],
[8., 7., 1., 6.],
[4., 9., 3., 9.],
[0., 8., 4., 5.]]]])
Output after max pooling:
tensor([[[[8., 6.],
[9., 9.]]]])
输入数据的形状: torch.Size([1, 1, 4, 4])
输出数据的形状: torch.Size([1, 1, 2, 2])更多阅读:卷积和池化后的数据维度。
【说明:本站主要是个人的一些笔记和代码分享,内容可能会不定期修改。为了使全网显示的始终是最新版本,这里的文章未经同意请勿转载。引用请注明出处:https://www.guanjihuan.com】